NJUOS:多处理器编程
http://jyywiki.cn/OS/2022/slides/3.slides#
thread.h 简化的线程 API
进程是资源分配的基本单位,linux线程其实是通过轻量级进程实现的LWP(light weight process),所有Linux内核的角度去看线程和进程并没有区别,只不过他和主线程共享一些资源,线程是最小的执行单位,调度的基本单位。同时也是资源竞争的基本单位。
具体的东西之前 https://grxer.github.io/2023/03/26/TLS-Hijack/ 里有讨论
|
POSIX线程库进一步做了一层封装,做了个main函数的析构函数阻塞进程等待
int pthread_create(
pthread_t * tidp, //新创建的线程ID指向的内存单元。
const pthread_attr_t * attr, //线程属性
void *(*start_rtn)(void *), //新创建的线程从start_rtn函数的地址开始运行,使用参数时我们通常会进行类型强转
void * arg //若上述函数需要参数,将参数放入结构中并将地址作为arg传入。
);//创建成功返回0,否则返回错误信息对应的非0宏
void类型的指针配合上类型强转给了我们更多的灵活性和自由性
pthread_t类型的线程tibp,是进程内部,识别标志,两个进程间,这个线程ID允许相同
pthread_create函数创建的线程默认非分离属性的,在非分离的情况下,当一个线程结束的时候,它所占用的系统资源并没有完全真正的释放,也没有真正终止。
只有在pthread_join函数返回时,该线程才会释放自己的资源。或者是设置在分离属性的情况下,一个线程结束会立即释放它所占用的资源。
int pthread_detach(pthread_t tid);分离一个线程,一个分离的线程是不能被其他线程回收或杀死的。它的内存资源在它终止时由系统自动释放。
int pthread_join(pthread_t thread, //指定等待哪个子线程结束,接收哪个线程的返回值,只能是非分离线程
void ** retval//接收参数返回值
);//成功返回0,否则返回错误信息对应的非0宏
一直阻塞调用它的线程,直至目标线程执行结束(接收到目标线程的返回值),阻塞状态才会解除。
如果一个线程是非分离的(默认情况下创建的线程都是非分离)并且没有对该线程使用 pthread_join() 的话,该线程结束后并不会释放其内存(系统)空间,这会导致该线程变成了“僵尸线程”。join后我们也必须手动清除程序分配的空间(堆等等)_attribute__关键字主要是用来在函数或数据声明中设置其属性。给函数赋给属性的主要目的在于让编译器进行优化。
使用编译时pthread 库需要加上-lpthread,因为pthread并非Linux系统的默认库
-lpthread 选项只是告诉编译器在链接时链接 pthread 库。
-pthread 将自动添加必要的编译选项和链接选项,以确保程序正确地使用 pthread 库,编译器会自动将 “-lpthread” 选项添加到链接命令行中,以确保在链接时链接 pthread 库。
创建线程使用的是哪个系统调用?
strace了一下
mmap(NULL, 8392704, PROT_NONE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0x7ffff73ff000 |
gdb跟了一下,最后系统调用函数clong3进内核syscall的时候是一个很奇怪未知的调用号


gdb调试多线程
https://sourceware.org/gdb/onlinedocs/gdb/Threads.html
线程独立的栈区
|
把输出缓冲区关了,起了四个线程,每个线程都会Tprobe作为入口点,tid在相对高地址栈上,把栈地址给了base,调用StackOverflow

n始终在在栈rbp-0x24偏移处,最后会递归自己,每1024次会计算一次n距离栈底的距离,没有终止条件,栈一直在栈,始终有一天会真正的stackoverflow,我们就可以估计栈的大小
我们可以通过pipe 把结果给sort排序
./stack-probe | sort -nk 6
- -k选择一列
- -n把某一列当作数字排序

猜测出栈的大小默认也就是8M
线程内存模型
一组并发线程运行在一个进程的上下文中,各自独立的线程栈的内存模型不是那么整齐清楚的。栈被保存在虚拟地址空间的栈区域中,线程栈是不对其他线程设防的,所以如果一个线程得到另一个线程的栈指针,也是可以进行访问修改
|
grxer@grxer ~/D/s/N/p3> gcc -g -o test test.c -pthread |
如何改变这个堆栈大小?
可以利用pthread_create第二个参数线程属性在创建线程时做操作
the attribute type is not exposed on purpose. */
typedef union
{
char __size[__SIZEOF_PTHREAD_CONDATTR_T];
int __align;
} pthread_condattr_t;没有公开类型,但是给我们了api
int pthread_attr_getstacksize(pthread_attr_t *attr, size_t *stacksize);
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
返回值0,-1分别表示成功与失败,这里的stacksize都是以byte为单位
int main() {
pthread_t id;
pthread_attr_t thread_attr;
size_t stacksize;
int res = pthread_attr_init(&thread_attr);
assert(!res);
res = pthread_attr_getstacksize(&thread_attr, &stacksize);
assert(!res);
printf("before:%zu\n", stacksize);
res = pthread_attr_setstacksize(&thread_attr,10485760);
assert(!res);
res = pthread_attr_getstacksize(&thread_attr, &stacksize);
assert(!res);
printf("after:%zu\n", stacksize);
}
grxer@grxer ~/D/s/N/p3> ./test
before:8388608
after:10485760我们这样去改造一下
thread.h就好
int res = pthread_attr_init(&thread_attr);
assert(!res);
res = pthread_attr_setstacksize(&thread_attr, 10485760);
assert(!res);
pthread_create(&(tptr->thread), &thread_attr, wrapper, tptr);

__thread浅谈
Thread Local Storage,之前劫持过tls来bypass canary,但是对底层理解并不深,这次有了新的体会,但是也只是浅谈,好多东西还没搞懂,要去补补保护模式
get_cur |
还是和fs段寄存器有关,其实准确来说,自从8086的实模式过后,cs ss ds es等段寄存器里面存的不再是为了满足20位地址总线和重定位的物理段基地址,在保护模式下变为了段选择字,现在更应该叫段选择器,保护模式下会有用户态不可见的部分,叫做描述符高速缓冲器(是一个缓存,每次进行段解析后保存再里面),由处理器自动使用,而真正的段地址就在这里面
有以下方式去获得fs段地址
>>>通过内联汇编的方式
>>>系统调用int arch_prctl(int code, unsigned long *addr)
|
>>>gdb的fsbase命令或p/x pthread_self()获得这个值
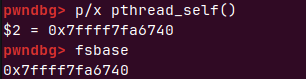
这里才惊奇的发现gdb里可以直接运行c函数
可以看到POSIX线程库的pthread_create返回给我们的tidp是每个线程的fs段地址
观察一下程序里定义的__thread变量和汇编里的关系
__thread char *base, *cur; // thread-local variables |
在fs-8处开始排列,他的下面也就是我们的之前看的canary和__exit_funcs析构函数组的key,pthread_create去创建一个进程是用mmap一块内存当作堆栈,fs则位于这个堆栈的高地址处,也就是堆栈的底部
原子性的丧失
|
就连单处理器并发都得不到正确的结果。taskset -c cpu-cpu <command>限制在cpu-cpu个处理器上运行
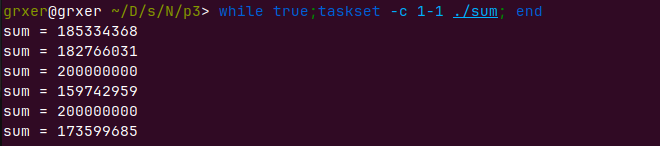
多处理器线程在并行,偏差更大
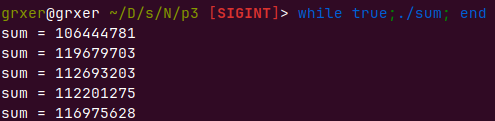
具体来说,当一个线程正在读取sum的值时,另一个线程可能已经修改了sum的值,但是第一个线程并不知道。这可能导致一个线程覆盖了另一个线程的结果,从而导致最终结果错误。
sum++翻译为汇编是三条指令,取出,+1,写回,这也就是我们单处理器为什么会出错原因
.text:000000000000145A 48 8B 05 DF 31 00 00 mov rax, cs:sum |
我们用内联汇编把sum++改为一句
asm volatile("add $1,%0":"+m"(sum)); |
.text:000000000000145A 83 05 DF 31 00 00 01 add dword ptr cs:sum, 1 |
此时单核处理器没有多处理器乱序的并行,可以正常得到结果

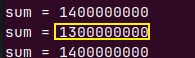
多核处理器依旧出差,不过误差低了一点
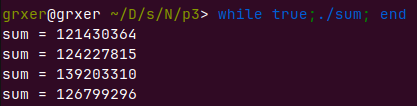
顺序的丧失
- 用gcc对程序进行-O1的优化发现每次运行结果都是sum = 100000000
.text:0000000000001223 |
-01的优化保留了循环,但是优化了每次写回内存的操作,用rcx寄存器代替
mov cs:sum, rcx最后写回的这一步决定了sum = 100000000
- -O2优化 每次运行结果sum = 200000000
.text:0000000000001290 ; void __cdecl Tsum() |
循环也没有了,直接把正确结果一个add,得到正确结果,但是这只是一个假象,和前面一句add汇编一样,当一个线程正在读取sum的值时,另一个线程可能已经修改了sum的值,我们只是两个线程去add,只是错误得几率很小,我们把线程增加到14,14次竞争add就已经有可见概率错误了
extern int done; |
这一一段代码我们只编译不链接
grxer@grxer ~/D/s/N/p3> gcc -c test.c |
没加优化,每一次都会把done取出来,判断done是否为0
-O1优化
grxer@grxer ~/D/s/N/p3> gcc -O1 -c test.c |
只进行了一次取出done,多次判断相当于
if(!(x=done)){ |
但是我们知道这个done为全局变量,万一被某个线程改掉了呢?就叛变了原本的逻辑
-O2优化
grxer@grxer ~/D/s/N/p3> objdump -d test.o |
更离谱了
if(!done){ |
解决办法
给编译器加一下限制
Memory Barrier
asm volatile (“” ::: “memory”)
volatile告诉编译器不要对这条指令优化
memory 表示指令以不可预测的方式修改了内存, 强制gcc编译器假设RAM所有内存单元均被汇编指令修改,这样cpu中的registers和cache中已缓存的内存单元中的数据将作废。cpu将不得不在需要的时候重新读取内存中的数据。
使用volatile变量
extern int volatile done;
volatile 指出 done 是随时可能发生变化的,每次使用它的时候必须从done的内存地址中读取,即使cache或寄存器里有
可见性的丧失
|
https://gcc.gnu.org/onlinedocs/gcc-12.2.0/gcc/_005f_005fatomic-Builtins.html
https://gcc.gnu.org/onlinedocs/gcc-4.4.7/gcc/Atomic-Builtins.html#Atomic-Builtins
原子变量及原子操作是c11引入,<stdatomic.h>
原子变量的操作是原子操作(atomic operation),原子操作指的是不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,在同一个cpu时间片中完成,中间不会有任何的上下文切换。用于实现高效、正确、线程安全的并发编程
Built-in Function: void __atomic_load (type *ptr, type *ret, int memorder) |
首先用来原子变量的flag的低两个bit当作开关
初始时为00,最低bit为1时T1打开,倒二bit为1时T2打开
Tsync是我们的控制线程中FLAG_XOR(3)同时把T1T2打开,然后T1T2同时执行,不管哪一个线程快一点慢一点,得到的结果只能是01 10 11,执行过后会把自己对应的开关置零关闭
根据该程序的状态机模型是不可能出现00的,但是
grxer@grxer ~/D/s/N/p3> gcc -O2 -g -o mem-ordering mem-ordering.c |
导致这方面的原因来自多核处理器的微架构 https://www.bilibili.com/video/BV1844y1z7Dx
为了实现流水线,需要一条指令拆分为更小的可执行单元,叫做micro-operations简称uOps,利用寄存器重命名和分支目标预测的技术,实现超标量乱序执行。
在代码级上,看上去似乎是一次执行一条指令,但是实际上是指令级并行,呈现出一种简单的顺序执行指令的表象。正好能获得机器级程序要求的顺序语义模型的效果。
具体到我们上面的程序
# <-----------+ |
我们FLAG_XOR(3)后,在多处理器系统中,当一个CPU对共享内存进行修改时,需要使其他CPU中的缓存无效,导致movl $1, %0;几乎总是cache miss的,cpu在找内存同时执行下一条和上一条无关的指令,导致了输出0
"movl $1, %0;" // y = 1 |
实现一致性
Memory barrier:__sync_synchronize()
Built-in Function: void __sync_synchronize (…)
This built-in function issues a full memory barrier.
static inline void __sync_synchronize (void)
{
/* This issues the "mfence" instruction on x86/x86_64. */
__asm__ __volatile__ ("mfence" : : : "memory");
}我们之前在解决顺序性,用到的asm volatile (“” ::: “memory”)引导编译器,而我们这次需要和硬件进行交流
防止这种CPU乱序,我们需要添加CPU memory fence。X86专门的memory fence指令是”mfence”;保证存访问操作完成后才能执行后续的内存访问操作
"movl $1, %0;" // x = 1
"mfence;"
"movl %2, %1;" // y_val = ygrxer@grxer ~/D/s/N/p3> ./mem-ordering | head -n 10000 |sort| uniq -c
1462 0 1
221 1 0
8317 1 1原子指令
和我们的flag一样用原子变量
stdatomic.h