2023 *ctf pwn
师傅们tql,题解出的太快了,orz
https://github.com/sixstars/starctf2023/tree/main
fcalc
grxer@Ubantu20 ~/s/m/s/fcalc> checksec ./fcalc |
这里有个溢出
void *buf; // [rsp+30h] [rbp-28h] |
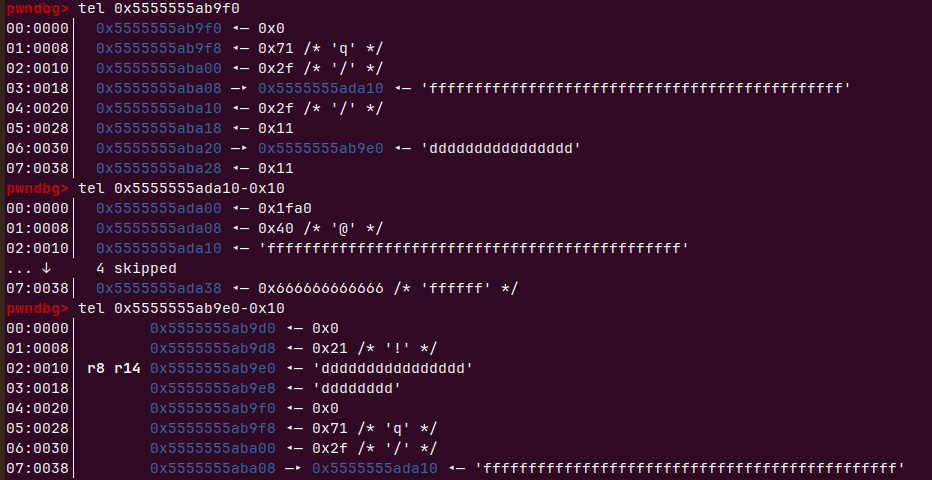
然后就是在运算符号为0时会溢出原来定义的函数数组会跳转到0040E0处的数据执行
_BYTE v6[12]; // [rsp+8h] [rbp-50h] BYREF |
40E0处存的一个栈地址,栈上是有可执行权限的,可以通过溢出往栈上写shellcode,shellcode按双精度浮点数解释需要满足下面的条件
v13 = fabs(*v10); |
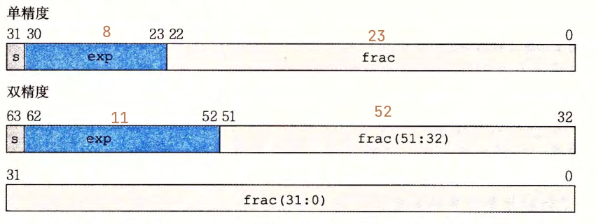
浮点数里有exp阶码全为1,有效数不全为0,表示Nan(not a number)
对于nan的一些特性 x:including NaN and ±∞
| Comparison | NaN ≥ x | NaN ≤ x | NaN > x | NaN < x | NaN = x | NaN ≠ x |
|---|---|---|---|---|---|---|
| Result | False | False | False | False | False | True |
所以只要浮点数的高位为0x7ff或0xfff即可
浮点数的低位再利用跳转指令跳转到shellcode即可,大概找到下面可以用的跳转指令



计算偏移
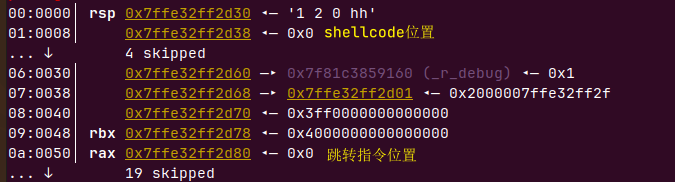
p/x 0x7ffe32ff2d38-(0x7ffe32ff2d80+2) |
from pwn import * |
方法2
根据浮点数的解释规则来看,在有效数都为0时,阶码最小3FF(1023),有效数都为1,最大也就无限接近2,所以阶码最大为1023+log2(100/2)=1,028.643 即404h多
REX前缀的值介于40h到4Fh之间,一条指令只能有一个REX前缀,必须紧接在指令的第一个操作码字节之前。 REX前缀在其他任何位置都将被忽略。
40的前缀是可以使用的,当我们用\x40覆盖某些指令时可以转义或被忽略(相当于nop)
这边至少要开头两个0x40才能构成0x404的开头绕过检查,所以单句的payload不能大于6个字节
shellcode = asm(''' |
方法3
官方paylaod是构造了jmp 4来跳到下一条指令
>>> disasm(b"\xEB\x02") |
jmpn = b"\xEB\x02" |
小于四字节的可以用nop来填充
starvm
第一次接触vm pwn,是一个c++写的哈佛架构的虚拟机,c++的stl逆向好难懂,但是vm pwn最主要的就是逆清楚虚拟机结构体和指令操作,难搞哦
typedef struct{ |
指令储存和数据储存分开,先初始化code后初始化data,然后就是取指令 译码 执行 更新pc的操作
vector的结构
00000000
00000000 _M_start dq ?
00000008 _M_finish dq ?
00000010 _M_end_of_storage dq ?
00000018 vector ends
漏洞是data初始化时没有限制数字,在6 7指令会导致申请的堆的越界读写,10指令没有检查值会寄存器越界覆盖掉mem指针,漏洞都可以造成任意地址读写
case VM_LOAD:6 |
ex师傅那里的思路就是mallocgot为setvbuf,setvbufgot为system,然后修改sevbuf参数stdin指向字符串sh,最后再把mem指针置零触发maloc
from pwn import * |
由于一开始给了栈地址,就想着修改返回地址为ogg,但是glibc2.35的ogg太难用了,没一个成功
from pwn import * |
有个syscal ret的gadget做后门可以写rop链
from pwn import * |
drop
去符号表的rust程序,基本看不懂反汇编,只能配合gdb调试现象来看
第一次先添加了ffff,又添加了dddd,发现是申请了一个0x71大小的堆块来做管理结构,堆块的大小和输入的内容相关